
Verslag workshop architectuur en technologie
Lees hier verder voor een samenvatting van de workshop over technologie en architectuur tijdens de trefdag met de erfgoedsector over het virtuele museum van Vlaanderen op 21 november 2022.
Vraag 1: waarom heb je voor deze workshop gekozen
De meeste deelnemers spelen zelf een rol in de digitaliseringsinitiatieven van hun organisaties. Samenvatting van de antwoorden:
- Op zoek naar inspiratie voor of raakvlakken met de digitaliseringsplannen van de eigen instelling.
- Begrijpen hoe de architectuur aansluit op andere technische platformen in erfgoedland.
- Inzicht krijgen in de (meta)data-architectuur.
- Interesse in de technologie achter het platform.
- Inzicht in de aansluiting bij het beleid rond digitalisering.
Toelichting bij de architectuur
Het overzicht van de architectuur toont welke componenten we in versie 1 van het museum willen voorzien (wit), en wat er later kan volgen (grijs):
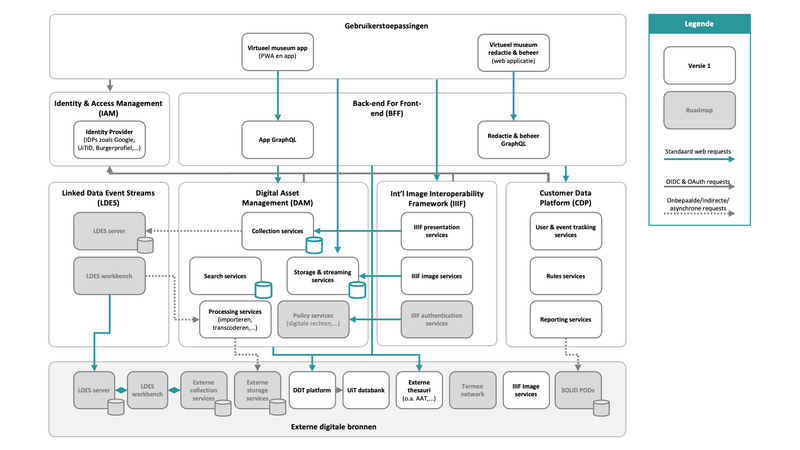
- In versie 1 voorzien we twee gebruikerstoepassingen: een webapplicatie voor redacteurs waarin ze erfgoedbelevingen aanmaken en beheren, en een publiekstoepassing die als progressive web app (PWA) en als PWA in een native shell app voor iOS en Android. De PWA garandeert een laagdrempelige instap via een browser, de installatie van de native app later zorgt voor toegang tot belevingen die smartphone-capaciteiten aanroepen die nog niet vanuit een browser toegankelijk zijn.
- Voor efficiëntie en veiligheid spreken de gebruikerstoepassingen de back-end aan via een back-end for front-end. Dat vereenvoudigt ook de evolutie van die toepassingen, en koppeling met eigen toepassingen en die van derden.
- De registratie en toegang voor beide toepassingen wordt bemiddeld door een Identity en Access Management component die met verschillende courante identity providers gekoppeld wordt. In het bijzonder voor het publiek willen we het aanmaken van een profiel zo eenvoudig mogelijk maken. We houden daarbij rekening met ontwikkelingen in Vlaanderen wat betreft Solid PODs voor het beheer van gebruikersgegevens.
- In de publiekstoepassing moedigen we gebruikers aan zich te registreren en enkele gegevens te delen (locatie en interesses) zodat we gesuggereerde erfgoedbelevingen kunnen personaliseren, de vooruitgang van gebruikers opvolgen en via beloningen en andere mechanismen hun verdere verkenning erfgoed stimuleren. Hiervoor voorzien we een Customer Data Platform dat ook de analytics-capaciteiten omvat waarmee we de eigen werking doorlopend verbeteren, en we geanoniemiseerde gebruikersinzichten kunnen delen met de erfgoedsector.
- De kern van de back-end is het digital asset management systeem, dat functies aanbiedt voor het beheer en doorzoeken van assets en content, opslag en streaming, en bewerkingen van assets. In een volgende fase willen de toepassing van policies automatiseren, bv. op basis van de auteursrechten op assets.
- Gezien de groeiende adoptie van open data binnen en buiten erfgoedland, willen we van bij het begin inzetten op standaarden rond linked open data, waaronder OSLO en linked data event streams. We willen dus geen silo of aggregator zijn, maar als een decentrale digitale 'collectie' erfgoedassets kunnen linken en hergebruiken uit andere bronnen en omgekeerd. We beginnen in versie 1 met erfgoedgerelateerde UiT evenementen die we aanroepen via het uitwisselingsplatform dat door het departement voor het initiatief Doelgericht Digitaal Transformeren opgezet wordt.
- Als onderdeel van die openheid en decentralisatie willen we beeldmateriaal via IIIF services kunnen hergebruiken.
Vragen bij de toelichting:
- Hoe zal het platform gedeployed worden? Dat ligt nog niet vast, maar de opzet leent zich tot containerisatie via bv. Kubernetes. De deployment zal in overleg met de platformbouwer bepaald worden.
- Hoe passen de prototypes in deze architectuur? De prototypes zijn losstaande ontwikkelingen waarmee we naast andere dingen ook technische en architecturale keuzes wilden testen. Verhalen en uitdagingen willen we volledig redigeren en beheren in versie 1 van het platform, terwijl AR- en spelbelevingen wel in de gebruikerservaring geïntegreerd worden, maar aanvankelijk buiten het platform ontwikkeld worden. Metadata van alle belevingen en van de assets waaruit ze samengesteld zijn, worden in het platform beheerd en als open data gedeeld.
- Is het de bedoeling dat instellingen al hun data en assets delen? Nee, elke instelling bepaalt zelf wat ze wel of niet deelt.
Bekijk ook de ochtendpresentatie over de principes achter de architectuur.
Vraag 2: welke content uit je eigen digitale collectie zou je kunnen uitwisselen met dit platform?
- Schilderijen, beelden en collectiestukken die kunnen gelinkt worden aan een locatie.
- Andere digitale collecties in het algemeen.
- Ook audiovisueel materiaal, mits bronvermelding.
- Documentair materiaal zoals architectuurplannen, bouwplannen, foto's.
- Typografisch erfgoed, zoals kranten en manuscripten.
- De metadata van deze content.
Vervolgdiscussie:
- Is het de bedoeling om assets uit externe bronnen te aggregeren, of om ze te linken? We willen geen silo opzetten, maar een decentrale 'collectie' die steeds meer kan linken naar andere bronnen naarmate ze verder digitaliseren en standaardiseren op open data.
- Is de architectuur niet te uitgebreid voor een kleine set content? Het aantal belevingen zal voortdurend groeien. De digitalisatie van externe bronnen is nog volop aan de gang, met verschillende snelheden, dus we gaan toch nog een hele tijd zelf assets moeten kunnen beheren. En zoals je aan de prototype kan zien, kunnen we niet altijd bestaande assets één op één hergebruiken, en zullen we ook eigen assets creëren, beheren en delen.
- Verwachting dat uitwisseling vraaggestuurd is: wat is er nodig voor het verhaal dat een beleving brengt? Dat klopt. Het zou al een voordeel zijn als het eigen redactieteam van het virtuele museum toegang heeft tot externe bronnen. We gaan er niet van uit dat er al van bij de start op grote schaal een automatische discovery en linking van assets mogelijk is, maar op termijn willen we daar wel naar toe.
Vraag 3: welke componenten zou je kunnen hergebruiken voor je eigen werking?
- De voorgestelde architectuur heeft verschillende componenten gemeen met die van andere instellingen, maar bv. de processing services en het Customer Data Platform zijn minder courant. Het zou interessant zijn om geanoniemiseerde gebruikersdata te kunnen bekijken.
- De vraag kan ook omgekeerd gesteld worden: welke componenten kan de architectuur van het virtuele museum hergebruiken?
- Het zou interessant zijn om een zicht te hebben op de erfgoedelementen in de eigen collectie die aan een verhaal in het virtuele museum gelinkt zijn.
Vervolgdiscussie:
- Herbruikbare componenten zijn een mooie intentie, maar wie gaat die beheren? In het kader van de Business Cases voor Digitale Collecties (gedeeld initiatief departement CJM en Digitaal Vlaanderen) zijn we aan het bekijken hoe het beheer voor hergebruik kan georganiseerd worden.